让传统戏曲“可听、可看、可计算”:中国传统戏曲多模态知识图谱与智能识别
- 2026-06-25 17:17:19
【顶刊速读】
6.22
2026
ELSEVIER |Journal of Cultural Heritage
可持续城市形态中的空间度量与方法:系统综述
【导读】研究以国家级非遗传统戏曲为对象,将文本、图像、音乐链接、主题与情感组织进同一知识图谱,并提出统一模型自动识别戏曲作品的情感和体裁,为传统戏曲的数字化整合、展示与持续更新提供了一条完整技术路径。

【关键词】
数字人文;传统戏曲;多模态知识图谱;情感识别;体裁识别
亮点
Part.1
1、构建了融合文本、图像、音乐链接、主题和情感的中国传统戏曲多模态知识图谱 OpeMKG;
2、提出具有深层语义的传统戏曲本体 OpeOnto,使知识图谱不再停留于时间、地点、人物等基础信息描述;
3、设计统一的 SGRM 模型,通过歌词与音频频谱融合、注意力机制和多任务学习,同时识别作品情感与戏曲体裁;
4、汇聚 171 个国家级传统戏曲项目、473 个子项目、28,989 张图片、4,500 余部作品,并最终生成 35,558 条知识三元组。
Abstract
摘要
传统戏曲数字资源不断增长,但数据分散在不同网站和平台,文本、图像与音频之间缺乏有效关联。为缓解这一问题,研究首先构建包含“主题”和“情感”等深层语义的传统戏曲本体 OpeOnto,随后整合国家级非遗项目、图片和音乐作品等多源数据,形成多模态知识图谱 OpeMKG。
在此基础上,作者进一步提出融合歌词与音频频谱的情感—体裁识别模型 SGRM,以多模态融合和多任务学习同时完成情感识别与剧种识别。
实验结果显示,SGRM 的情感识别 F1 值为 78.76%,体裁识别 F1 值为 96.64%,两项任务平均 F1 值达到 87.70%,优于多种基线模型。该研究将知识组织、文化展示与自动更新连接起来,为非物质文化遗产的数字化保护提供了可复用框架。

1
研究背景
Research Background
传统戏曲集语言、唱腔、动作、音乐与舞台视觉于一体,是典型的多模态非物质文化遗产。随着数字化记录不断推进,相关网站和数据库积累了大量资料,但这些资源往往彼此分离:项目介绍存在于非遗名录网站,图片散落于搜索平台,音频与歌词保存在音乐平台。普通读者很难从零散信息中建立对剧种、作品、传承人、地域、主题和情感之间关系的整体认识。
已有文化遗产知识图谱大多以文本为核心,描述时间、地点、人物和文献等基础属性,对作品中的主题、情感等深层语义关注不足,也缺少图像和音频等模态。另一方面,戏曲作品还在持续产生,若完全依赖人工判断其剧种和情感,知识图谱很难及时更新。研究因此提出一个连贯目标:先建立可复用的戏曲本体,再构建多模态知识图谱,最后用智能模型为新增作品自动补充情感与体裁标签。
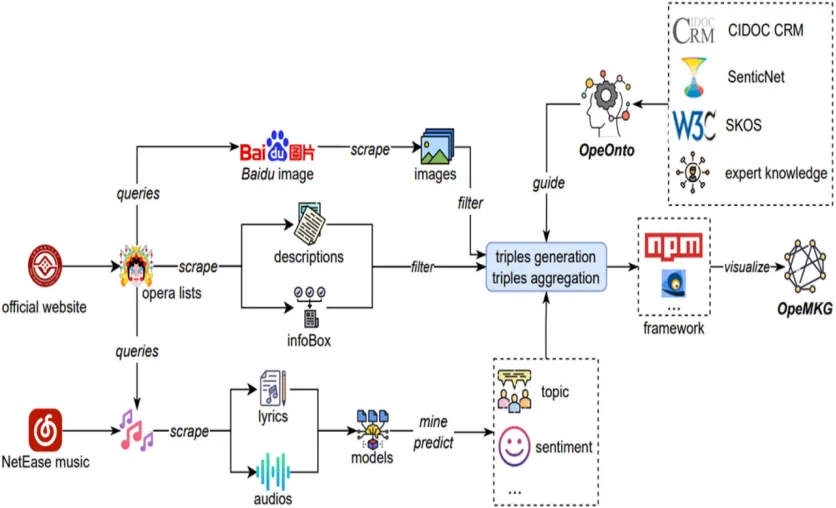
图1 传统戏曲本体与多模态知识图谱构建框架
2
研究方法与模型路径
Methods
一、研究方法
1.构建深层语义本体 OpeOnto
研究以文化遗产领域通用的 CIDOC CRM 为语义基础,并引入 SKOS 与 SenticNet 中的概念,形成传统戏曲本体 OpeOnto。其核心类别包括剧种、作品、地点、传承人、时长、文献、图像、标识符、主题、情感和时间跨度。与只记录“谁、何时、何地”的传统本体相比,OpeOnto 将作品的主题和正负向情感纳入概念模型,使知识图谱能够表达更接近作品内涵的知识。
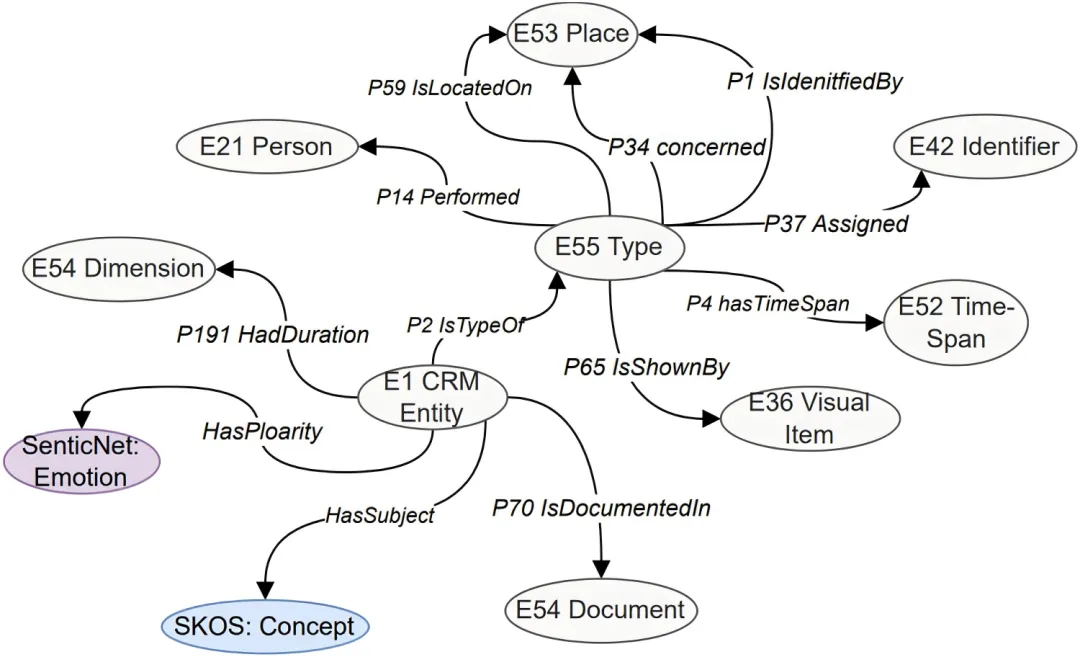
图2 传统戏曲概念模型 OpeOnto
2.多源采集与知识三元组生成
作者从官方非遗网站采集国家级传统戏曲项目及其属性信息,共获得 171 个项目和 473 个子项目;对 325 个去重后的剧种名称进行图像检索,经人工核查后保留 28,989 张相关图片;同时从音乐平台采集 4,500 余部不同剧种的作品及其音频和歌词。基础属性可直接转化为“头实体—关系—尾实体”三元组,作品时长等信息则通过音频工具提取。

图3 昆曲项目页面及多源数据采集示例
3.主题、情感与知识图谱可视化
在深层语义提取方面,研究对歌词进行分词和停用词处理,再利用 LDA 主题模型识别作品主题。通过困惑度调参,最终将主题数设为 9,代表性主题包括社会弊病、美好爱情与社会正义。情感标签则由后续训练的 SGRM 模型预测。所有来源的三元组汇总后形成 35,558 条记录,并被可视化为 OpeMKG。
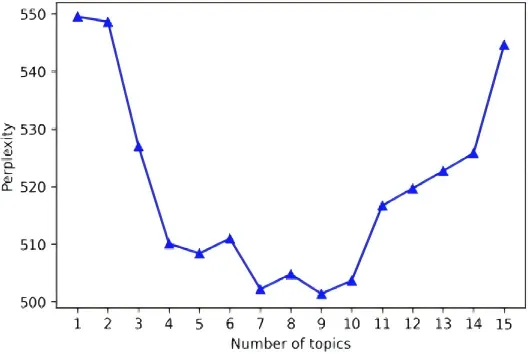
图4 LDA主题数量的困惑度调参结果
OpeMKG 以“传统戏曲”为中心连接不同剧种、地域、传承人、作品和属性。用户点击剧种节点可以查看图片与介绍;点击具体作品节点,还可看到音乐链接、主题和情感等信息。这种交互方式把原本散落在多个平台上的资源组织为可探索的知识网络。
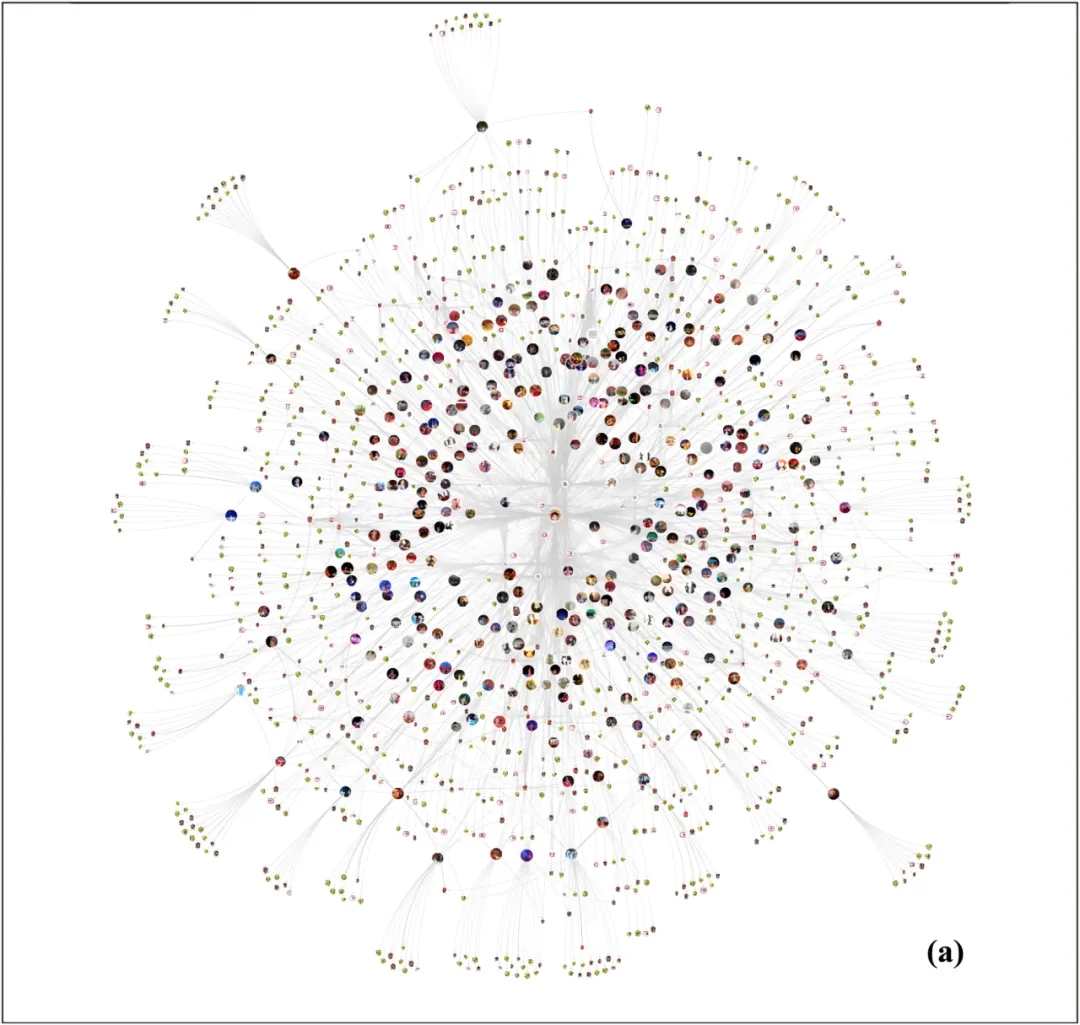
图5 OpeMKG总体结构
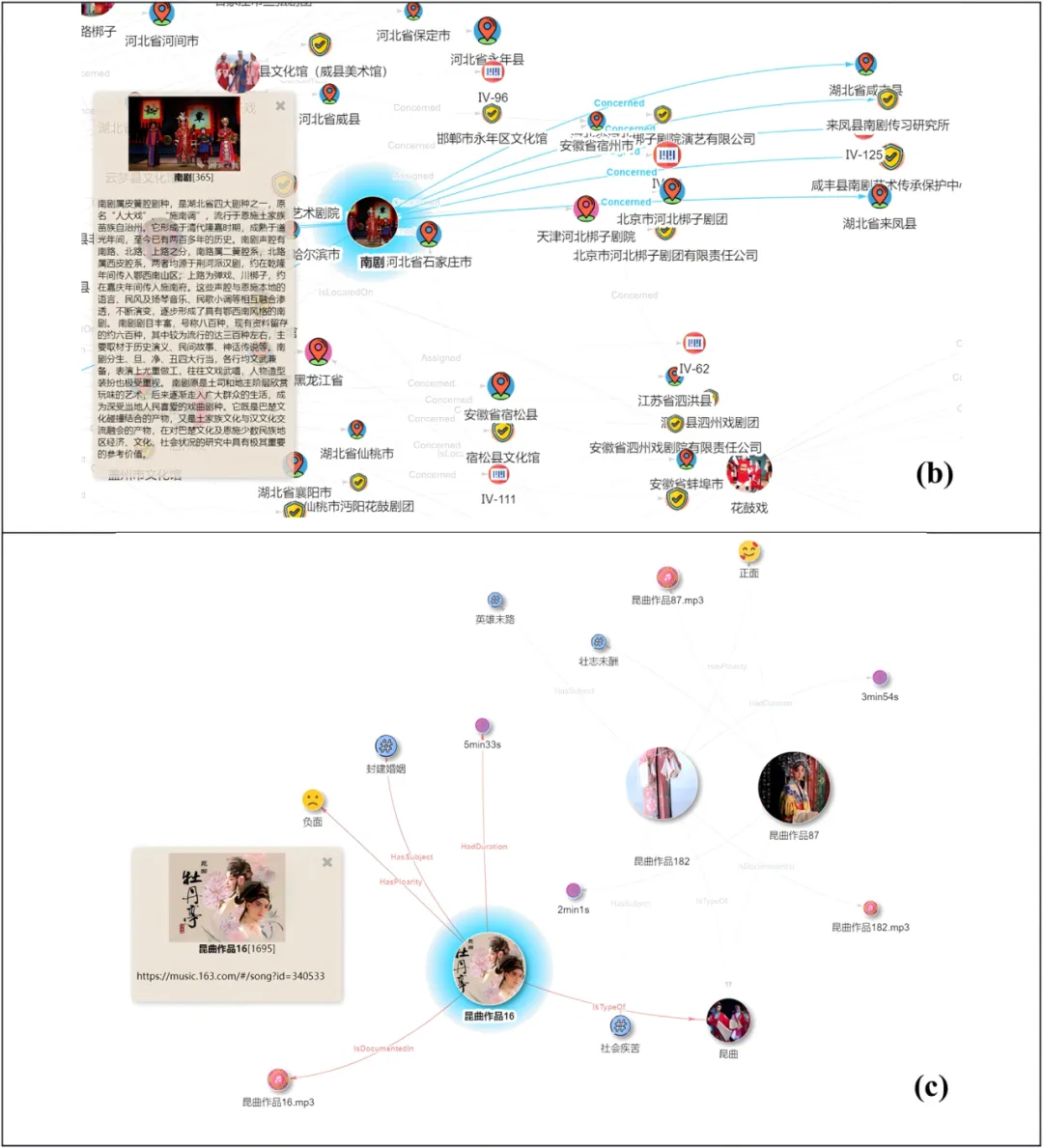
图6 OpeMKG中的剧种节点与作品节点示例
4.情感—体裁统一识别模型 SGRM
为支持知识图谱自动更新,研究设计了 SGRM,同时完成情感识别和体裁识别。模型包含四个环节:首先,使用 BERT 表示歌词,并采用“词—句—歌词”的层级结构;其次,将音频转换为频谱图,利用预训练 VGG19 提取频谱特征;再次,歌词端使用层级注意力网络筛选更有信息量的词句,频谱端使用视觉注意力聚焦关键声学区域;最后,通过中间层张量融合与决策层加权融合整合两种模态,并借助多任务学习共享表示。
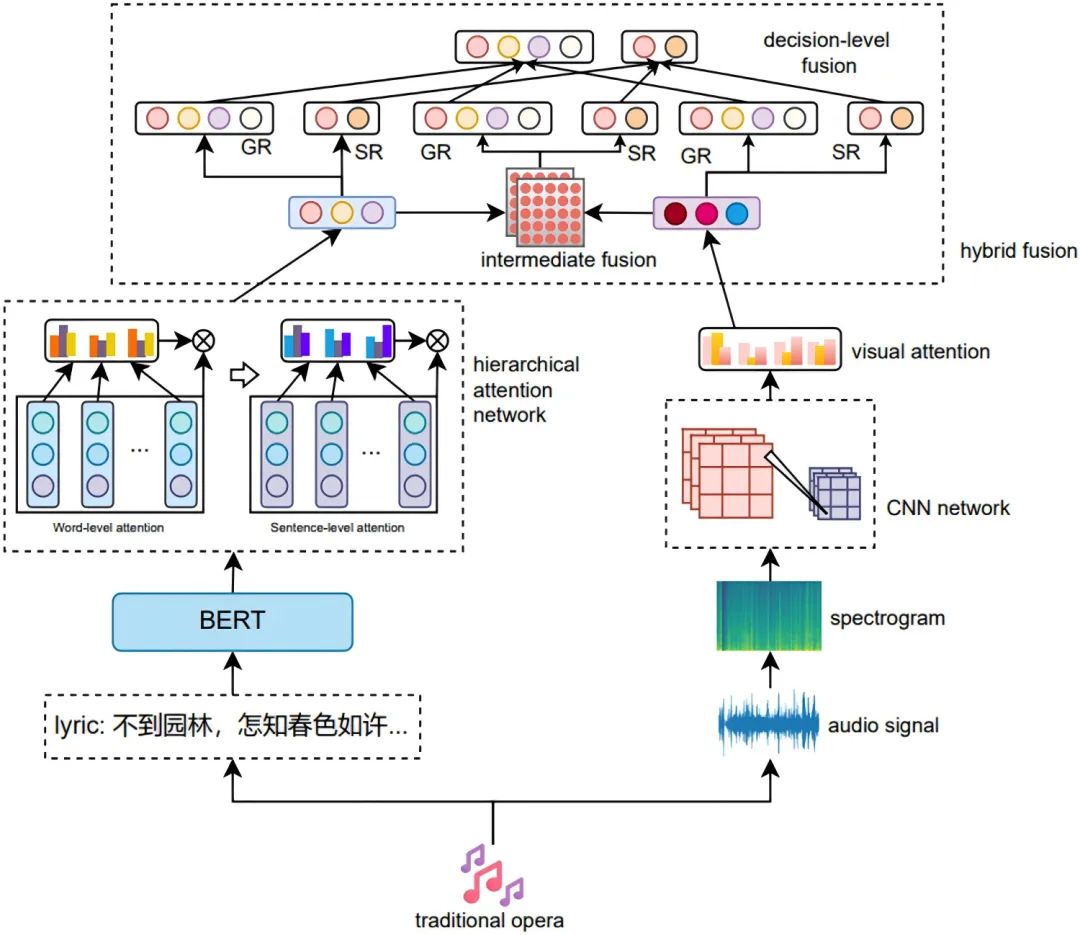
图7 SGRM 模型结构:歌词、频谱、多模态融合与多任务输出
二、训练数据与实验设置
实验聚焦京剧、晋剧、越剧和昆曲四类作品。依据清洗后的数据统计,共保留1,300部作品,其中京剧376部、晋剧285部、越剧289部、昆曲350部。情感标签由两名信息科学专业研究生独立标注,意见不一致时引入专家判断,双人标注Kappa系数为0.7925。最终数据包括537部正向情感作品和763部负向情感作品,并按70%∶30%划分训练集与测试集。需要注意的是,论文表2所列剧种数量与6.1节清洗后统计不一致,本文采用与情感标签总量一致的1,300部清洗后样本作为口径。
模型采用 BERT 表示歌词、VGG19 表示音频频谱,优化器为 Adam,学习率 0.001,训练 100 个 epoch,批量大小为 8。评价指标采用宏平均精确率、召回率和 F1 值,并与 EF/LF-LSTM、TFN、BERT、HAN、CCR、MGCER、GResNetM 等基线进行比较。
研究结果
Part.2
01
情感识别与体裁识别均取得最佳表现
SGRM 的情感识别精确率、召回率和 F1 值分别为 78.66%、78.89% 和 78.76%;体裁识别对应指标分别为 96.77%、96.57% 和 96.64%;两项任务平均 F1 值为 87.70%,在全部比较模型中表现最佳。
结果还呈现出一个有意思的差异:在情感识别中,歌词比频谱承载了更直接的情感信息;在体裁识别中,歌词与频谱的单模态表现接近,说明不同剧种不仅在唱词表达上有差异,也具有鲜明的声学特征。将两种模态结合后,模型能够同时利用语义线索和音乐线索。
02
多模态融合与多任务学习缺一不可
消融实验表明,只使用频谱特征时平均 F1 为 71.56%,只使用歌词特征时为 81.82%;加入多模态融合后,性能明显提升。去除多任务学习后平均 F1 为 84.73%,完整模型则达到 87.70%,提高 2.97 个百分点。这说明多任务学习不仅节省了分别训练两个模型的资源,也有助于减少噪声和过拟合。
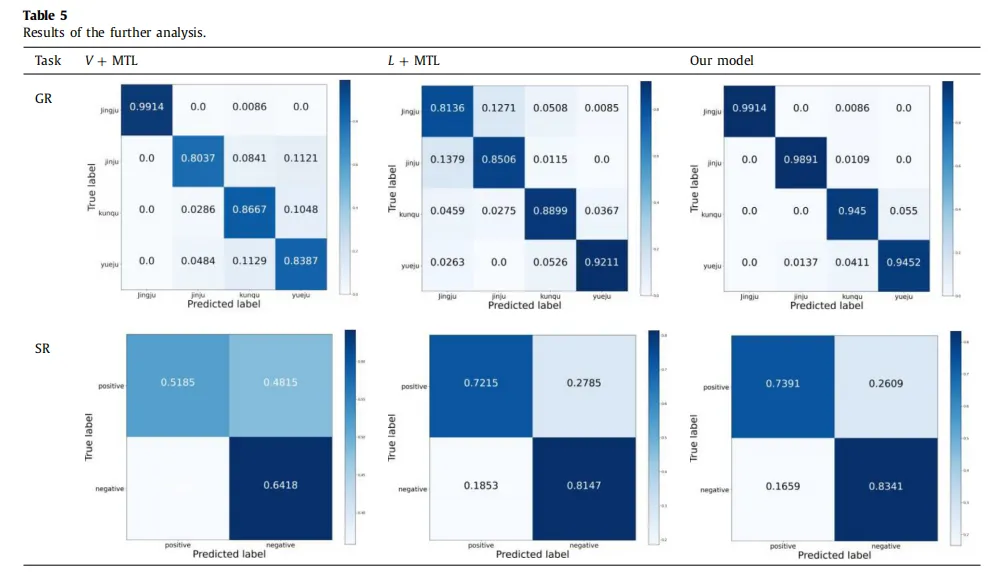
图8 不同模型在体裁与情感类别上的混淆矩阵对比
研究讨论
Part.3
1、研究价值与贡献
这项研究的价值不只在于“做了一个分类模型”,而是把传统戏曲数字化中的三个环节连接起来:用本体规定知识如何表达,用多模态知识图谱整合分散资源,再用识别模型为新增作品自动补充标签。这样形成的系统既面向研究者,也面向普通公众,可通过图像、音乐和关系网络降低理解戏曲知识的门槛。
在数字人文层面,OpeOnto 基于 CIDOC CRM 构建,意味着它可以与采用相同语义框架的其他文化遗产知识图谱连接;主题与情感类别又使知识组织从基础属性走向作品内涵。对于其他具有文本、声音和图像资源的非遗类型,这套“本体—多模态知识图谱—自动识别”的技术路线也具有借鉴意义。
2、局限性与未来方向
从研究设计和数据来源看,本文仍存在一些值得进一步讨论的边界。情感目前只划分为正向和负向,难以覆盖戏曲中更细腻、复合的情绪;识别实验仅选取京剧、晋剧、越剧和昆曲四类剧种,模型对更多地方戏曲的泛化能力仍需验证;图像来自搜索平台,音乐与歌词来自商业音乐平台,数据质量、授权和长期可用性也需要进一步治理。作者明确提出,未来将持续扩充OpeOnto与OpeMKG,增加更多类别、节点和剧种,并进一步分析戏曲视频。
读后笔记
第一,知识图谱真正有价值的地方,不是把资料简单“放在一起”,而是通过本体建立稳定、可复用的关系规则。OpeOnto 将主题和情感纳入模型,使传统戏曲知识不再只是名录式展示,而是能够沿着“剧种—作品—主题—情感—音频—图像”的路径被理解和发现。
第二,论文将模型任务放进知识图谱更新的真实需求中。SGRM 不是孤立地追求分类精度,而是用来判断新作品属于哪个剧种、表达何种情感,并据此生成新的知识关系。这样的任务设计让人工智能与文化遗产保护之间形成了更清晰的应用闭环。
第三,多模态并不意味着简单堆叠数据。研究分别处理歌词的层级语义与频谱的声学视觉特征,再通过注意力机制、张量融合和决策层融合建立模态间联系。实验结果也说明,歌词更擅长传递情感,频谱则为体裁辨识提供了与歌词相近的重要信息。对传统戏曲这种“唱、念、做、打”高度综合的艺术而言,未来若进一步加入视频动作、舞台服饰和表演程式,知识图谱可能呈现出更完整的文化语境。
论文信息
Fan T, Wang H, Hodel T. Multimodal knowledge graph construction of Chinese traditional operas and sentiment and genre recognition[J]. Journal of Cultural Heritage, 2023, 62: 32-44.
DOI:https://doi.org/10.1016/j.culher.2023.05.003 IF: 3.3 Q1 B2
END
MultimodalknowledgegraphconstructionofChinesetraditional.pdf

